(See whitebrick-client for front end)
 |
 |
 |
 |
|---|---|---|---|
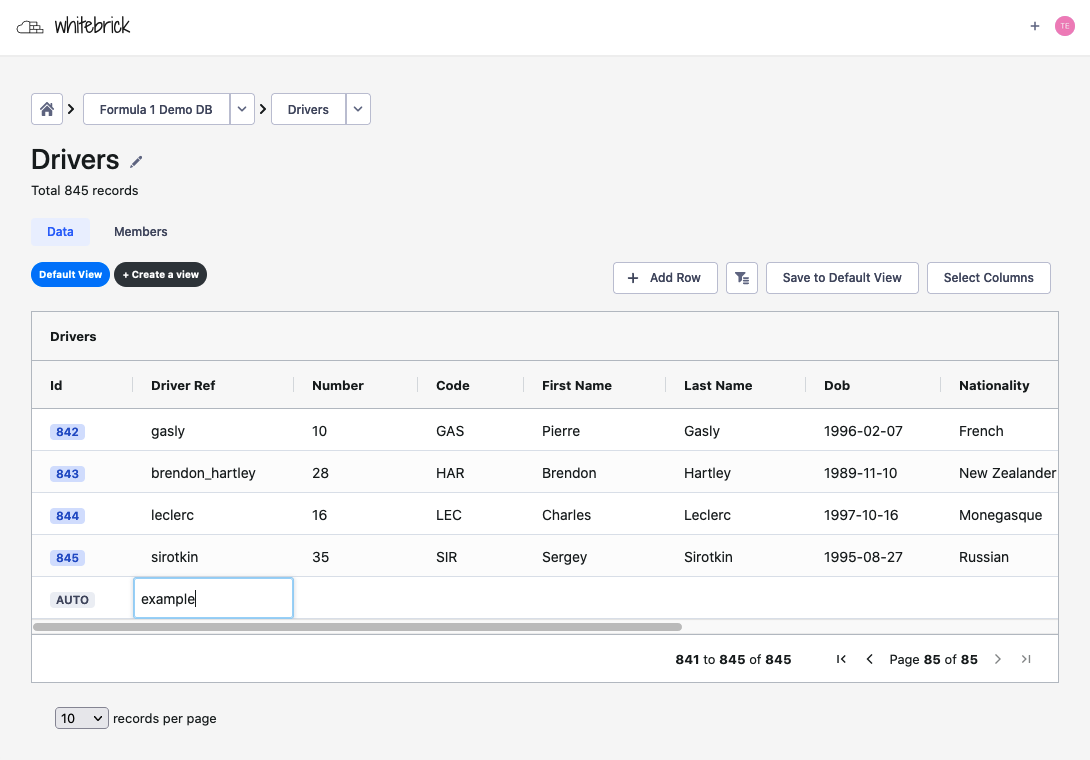
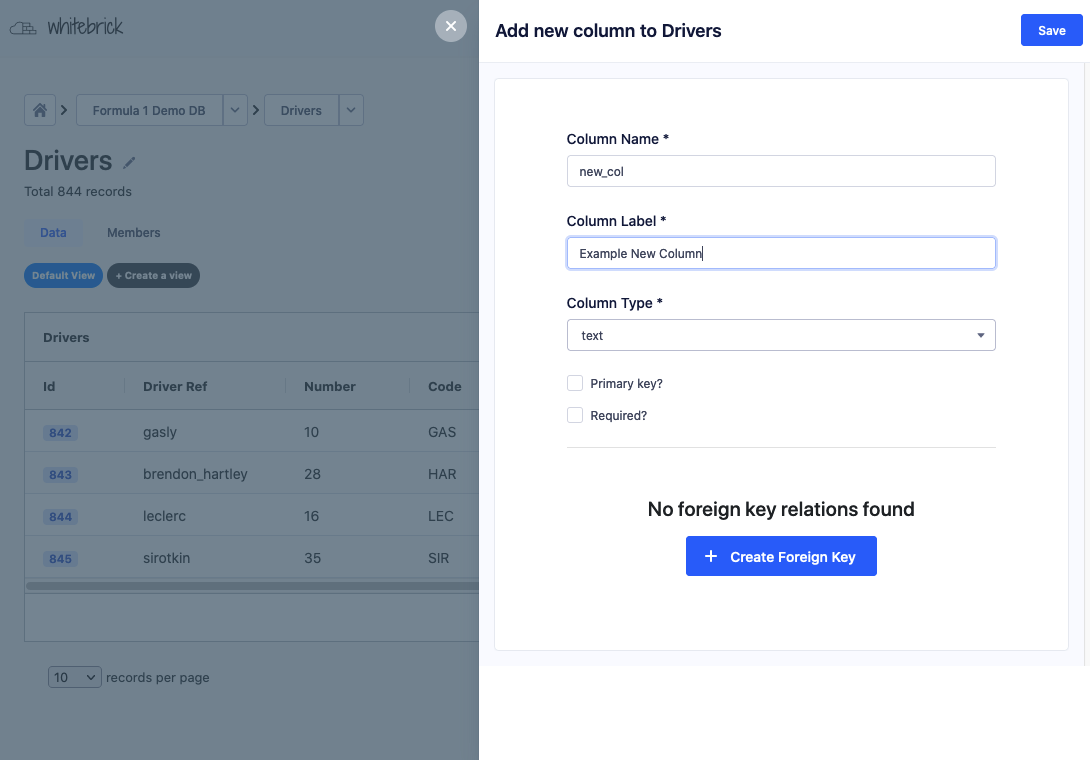
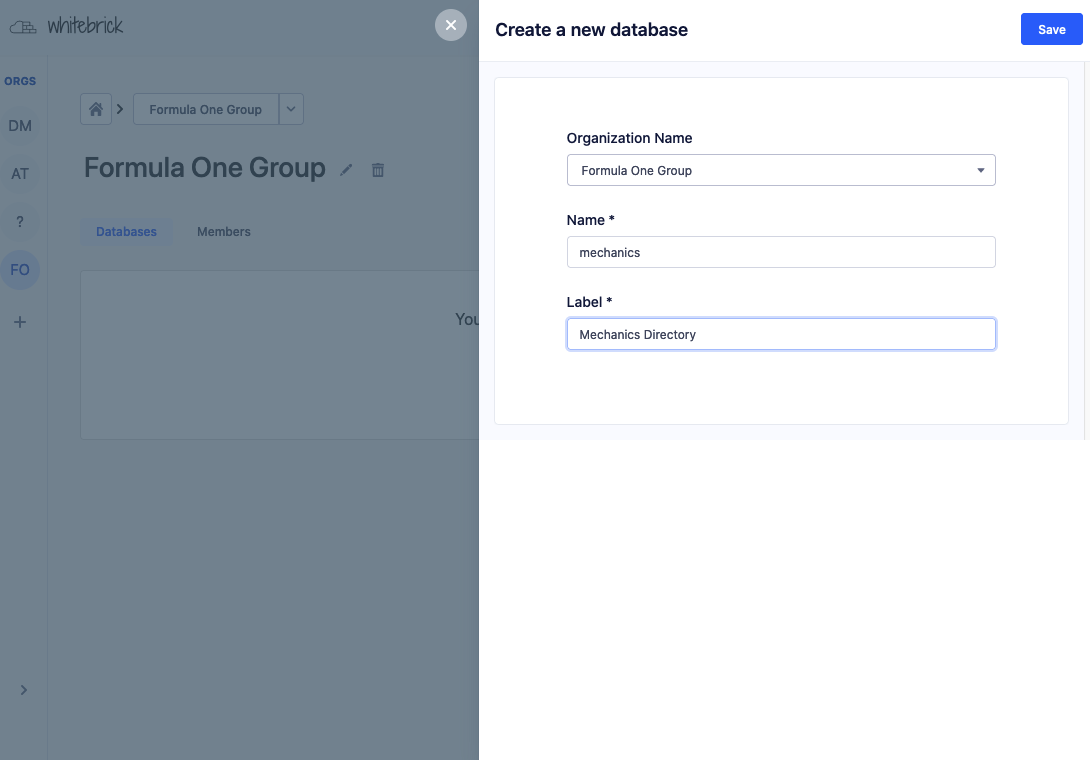
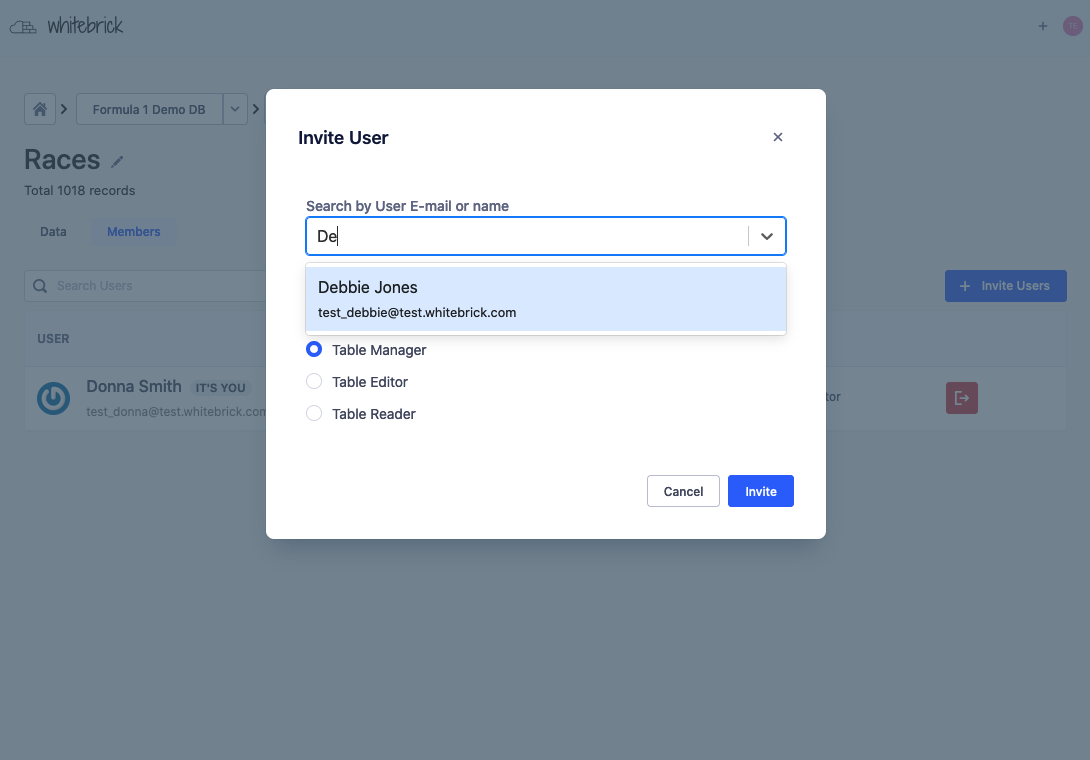
| Adding a record | Creating a column | Creating a DB | Managing access |
Points of difference:
- Gatsby static Jamstack client allows for easy customization with theme shadowing and simple, zero downtime deployment to static web servers.
- Hasura is leveraged for battle-tested table tracking, query processing and authentication and RBAC.
- The Serverless framework with Apollo GraphQL allows for rapid development of light-weight Lambda support functions.
- DDL Table & Column CRUD
- Live editing with subscription
- Table-level RBAC
- Joins
- Background process queue
- Background process UI
- UI styling and themes
- psql reader/writer access
- Validations
- Bucket file download columns
- Column-level RBAC
Whitebrick is licensed under the MIT License however dependency licenses vary.
- See https://github.com/whitebrick/whitebrick-client for front end
- Documentation
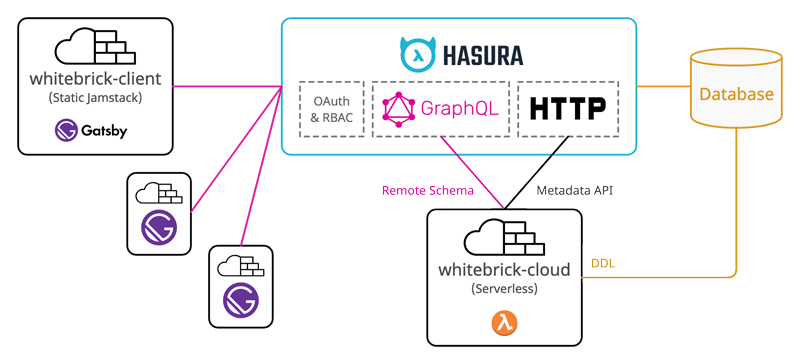
The Whitebrick No Code DB (Data Repository) comprises a front end Gatsby Jamstack client (whitebrick-client) and back end Serverless application (whitebrick-cloud) that adds multi-tenant DDL and access control functions to a Database via the Hasura GraphQL Server. The Jamstack client uses AG Grid as a spreadsheet-like UI that reads/writes table data directly from/to Hasura over GraphQL. Additional functions including DDL are provided by whitebrick-cloud Serverless functions that are exposed through the Hasura endpoint via schema stitching.
Hasura is an Open Source server application that automatically wraps a GraphQL API around a standard relational database.
Database Queries
Whitebrick queries Hasura to display table data and to update table records. When table data is queried, paginated, sorted and updated (mutated) this is processed by Hasura over GraphQL.
Schema Stitching & Remote Joins
Hasura also supports stitching schemas and passing requests on to other external endpoints. When Whitebrick requests DDL functions such as adding a new table or column, Hasura passes this request on to the Whitebrick Cloud Serverless app and then returns the response through the same single GraphQL endpoint.
Metadata API
Hasura provides a separate HTTP API that allows database metadata to be programmatically updated and refreshed. For example, when Whitebrick Cloud executes DDL commands to add a column to a table, it then calls this Hasura API to update the metadata so the new column can be tracked and queried over GraphQL.
Authentication & Authorization
Because Hasura stitches together multiple APIs under the one unified endpoint it is well placed to manage authentication and authorization. Hasura checks for credentials in a JWT issued by a third-party authentication provider.
The Whitebrick Cloud back end is a set of functions written in Javascript using the Apollo GraohQL interface and executed on a Serverless provider. Whitebrick Cloud connects with a database to make DDL calls such as creating new tables and columns. After modifying the database Whitebrick Cloud then calls the Hasura Metadata API to track the corresponding columns and tables. Whitebrick Cloud also manages additional metadata, background jobs, user permissions and settings, persisting them in a dedicated schema.
The Whitebrick front end is statically compiled Jamstack client written in Gatsby/React and uses AG Grid as the data grid GUI. Whitebrick sends GraphQL queries and mutations to the Hasura endpoint and displays the returned data. Because the client is statically compiled it can be easily customized by front end developers and deployed to any web site host.
- Refer to Hasura and Serverless documentation
-
Configure Postgres
Create a new database in PostgreSQL and ensure
pgcryptois in the search path (see Hasura requirements)CREATE EXTENSION pgcrypto;Make sure your database can be accessed from psql before proceeding (you may need to enable username/password authentication in pg_hba.conf) ie
$ psql -U <username> -h <host> -p <port> <db name> -
Run Hasura
Add the database credentials and run Hasura from Docker or Kubernetes and be sure to set a
HASURA_GRAPHQL_ADMIN_SECRET. Launching Hasura will create data definitions and values in thehdb_catalogschema of the database. If Hasura does not launch check and debug your DB connection/permissions with psql.Our Docker file looks something like this:
docker run -d -p 8080:8080 -e HASURA_GRAPHQL_DATABASE_URL=postgres://db_usr:[email protected]:5432/hasura_db -e HASURA_GRAPHQL_ENABLE_CONSOLE=true -e HASURA_GRAPHQL_DEV_MODE=true -e HASURA_GRAPHQL_ADMIN_SECRET=secret -e HASURA_GRAPHQL_UNAUTHORIZED_ROLE=wbpublic hasura/graphql-engine:latestNavigate to http://localhost:8080 and check the admin console is running (password is
HASURA_GRAPHQL_ADMIN_SECRETfrom above) -
Install Hasura CLI
Install the Hasura CLI but do not init new config
-
Configure .env File
Copy
./.env.exampleto./.env.developmentand complete with database connection parameters from (1) above. -
Create the wb Schema
Change to the
./hasuradirectory, copyconfig-example.yamltoconfig.yamland complete withHASURA_GRAPHQL_ADMIN_SECRETfrom (2) above. This config is used for the Hasura CLI. Now create the whitebrick-cloud schema "wb" by running$ bash ./scripts/apply_latest_migration.bash. After the migration is complete, change to the./dbdirectory and run$ bash ./scripts/seed.bashto insert the initial data. -
Run Serverless Listener
Run
$ bash scripts/start_dev.bashto start the serverless listener in local/offline mode. By default this listens to http://localhost:3000/graphql -
Track wb.table_permissions
From The Hasura console, use the top menu to navigate to the "Data" page, click to expand the default database on the left, then click the "wb" schema. Click the "Track" button next to the "table_permissions" table.
-
Add Remote Schema
From The Hasura console, use the top menu to navigate to the "Remote Schemas" page, click add and enter the endpoint displayed from (6) above, check forward all headers and set and long time-out of 1200 seconds. NB: If you are running Hasura in a local container you will need to use the corresponding URL eg
http://host.docker.internal:3000/graphql. If you now navigate to the "API" page from the top menu, In the query "Explorer" you should see queries beginning withwb*. -
Run Functional Tests
Download Karate (the stand-alone executable is all that is needed). Update
./test/functional/karate-config.jswith your Hasura endpoint URL from (2) above and then with Hasura running, change to the./test/functionaldirectory and run the command$ bash run_tests.bashThis creates a few test users and a small test schema
test_the_daisy_blog. Whitebrick is designed for incremental building-out of databases whereas this testing creates a database all at once so it can take time to run - up to 10 minutes in some cases. If karate lags make sure Hasura and/or it's container has plenty of RAM.To then add additional test data (northwind, chinook and DVD databases) as a second step run
$ bash run_tests.bash importDBs- this can take a additional 15 minutes. Or run$ bash run_tests.bash withImportDBsto run both in one hit.
- Questions, comments, suggestions and contributions welcome - contact: hello at whitebrick dot com