[TOC]
中文自然语言处理数据集,平时做做实验的材料。欢迎补充提交合并。
阅读理解数据集按照方法主要有:抽取式、分类(观点提取)。按照篇章又分为单篇章、多篇章,比如有的问题答案可能需要从多个文章中提取,每个文章可能都只是一部分,那么多篇章提取就会面临怎么合并,合并的时候怎么去掉重复的,保留补充的。
| 名称 | 规模 | 说明 | 单位 | 论文 | 下载 | 评测 |
|---|---|---|---|---|---|---|
| DuReader | 30万问题 140万文档 66万答案 | 问答阅读理解数据集 | 百度 | 链接 | 链接 | 2018 NLP Challenge on MRC 2019 Language and Intelligence Challenge on MRC |
| 2.2万问题 | 单篇章、抽取式阅读理解数据集 | 百度 | 链接 | 评测 | ||
| CMRC 2018 | 2万问题 | 篇章片段抽取型阅读理解 | 哈工大讯飞联合实验室 | 链接 | 链接 | 第二届“讯飞杯”中文机器阅读理解评测 |
| 9万 | 观点型阅读理解数据集 | 百度 | 链接 | 评测 | ||
| 1万 | 抽取式数据集 | 百度 | 链接 |
复旦大学发布的基于百度拇指医生上真实对话数据的,面向任务型对话的中文医疗诊断数据集。
| 名称 | 规模 | 创建日期 | 作者 | 单位 | 论文 | 下载 |
|---|---|---|---|---|---|---|
| Medical DS | 710个对话 67种症状 4种疾病 | 2018年 | Liu et al. | 复旦大学 | 链接 | 链接 |
包含知识对话、推荐对话、画像对话。详细见官网
之前的一些对话数据集集中于语义理解,而工业界真实情况ASR也会有错误,往往被忽略。CATSLU而是一个中文语音+NLU文本理解的对话数据集,可以从语音信号到理解端到端进行实验,例如直接从音素建模语言理解(而非word or token)。
数据统计:
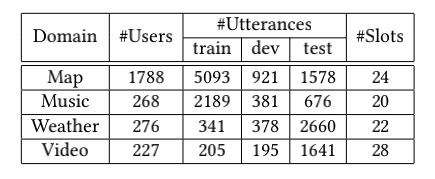
官方说明手册:CATSLU 数据下载:https://sites.google.com/view/CATSLU/home
中文呢真实商用车载语音任务型对话系统的对话日志.
| 名称 | 规模 | 创建日期 | 作者 | 单位 | 论文 | 下载 | 评测 |
|---|---|---|---|---|---|---|---|
| NLPCC2018 Shared Task 4 | 5800对话 2.6万问题 | 2018年 | zhao et al. | 腾讯 | 链接 | 训练开发集 测试集 | NLPCC 2018 Spoken Language Understanding in Task-oriented Dialog Systems |
这是一系类数据集,每年都会有新的数据集放出。
论文中叫FewJoint 基准数据集,来自于讯飞AIUI开放平台上真实用户语料和专家构造的语料(比例大概为3:7),包含59个真实domain,目前domain最多的对话数据集之一,可以避免构造模拟domain,非常适合小样本和元学习方法评测。其中45个训练domain,5个开发domain,9个测试domain。
数据集介绍:新闻链接
数据集论文:https://arxiv.org/abs/2009.08138 数据集下载地址:https://atmahou.github.io/attachments/FewJoint.zip 小样本工具平台主页地址:https://github.com/AtmaHou/MetaDialog
包含领域分类、意图识别和语义槽填充三项子任务的数据集。训练数据集下载:trian.json,目前只获取到训练集,如果有同学有测试集,欢迎提供。
| Train | |
|---|---|
| Domain | 24 |
| Intent | 29 |
| Slot | 63 |
| Samples | 2579 |
中文对话意图识别数据集,官方git和数据: https://github.com/HITlilingzhi/SMP2017ECDT-DATA
数据集:
| Train | |
|---|---|
| Train samples | 2299 |
| Dev samples | 770 |
| Test samples | 666 |
| Domain | 31 |
论文:https://arxiv.org/abs/1709.10217
- 今日头条中文新闻(短文本)分类数据集 :https://github.com/fateleak/toutiao-text-classfication-dataset
- 数据规模:共38万条,分布于15个分类中。
- 采集时间:2018年05月。
- 以0.7 0.15 0.15做分割 。
- 清华新闻分类语料:
- 根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成。
- 数据量:74万篇新闻文档(2.19 GB)
- 小数据实验可以筛选类别:体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
- http://thuctc.thunlp.org/#%E8%8E%B7%E5%8F%96%E9%93%BE%E6%8E%A5
- rnn和cnn实验:https://github.com/gaussic/text-classification-cnn-rnn
- 中科大新闻分类语料库:http://www.nlpir.org/?action-viewnews-itemid-145
| 数据集 | 数据概览 | 下载 |
|---|---|---|
| ChnSentiCorp_htl_all | 7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论 | 地址 |
| waimai_10k | 某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条 | 地址 |
| online_shopping_10_cats | 10 个类别,共 6 万多条评论数据,正、负向评论各约 3 万条, 包括书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店 | 地址 |
| weibo_senti_100k | 10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条 | 地址 |
| simplifyweibo_4_moods | 36 万多条,带情感标注 新浪微博,包含 4 种情感, 其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条 | 地址 |
| dmsc_v2 | 28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据 | 地址 |
| yf_dianping | 24 万家餐馆,54 万用户,440 万条评论/评分数据 | 地址 |
| yf_amazon | 52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据 | 地址 |
| 百度千言情感分析数据集 | 包括句子级情感分类(Sentence-level Sentiment Classification)、评价对象级情感分类(Aspect-level Sentiment Classification)、观点抽取(Opinion Target Extraction) | 地址 |
-
- 人名、地名、组织名三种实体类型
- 1998:https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/renMinRiBao
- 2004:https://pan.baidu.com/s/1LDwQjoj7qc-HT9qwhJ3rcA password: 1fa3
-
- 5 万多条中文命名实体识别标注数据(包括地点、机构、人物)
- https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/MSRA
-
SIGHAN Bakeoff 2005:一共有四个数据集,包含繁体中文和简体中文,下面是简体中文分词数据。
另外这三个链接里面数据集也挺全的,链接:
- 看方法主要还是转化为分类和ner任务。下载地址:https://aistudio.baidu.com/aistudio/competition/detail/47/?isFromLUGE=TRUE
| 数据集 | 单/多表 | 语言 | 复杂度 | 数据库/表格 | 训练集 | 验证集 | 测试集 | 文档 |
|---|---|---|---|---|---|---|---|---|
| NL2SQL | 单 | 中文 | 简单 | 5,291/5,291 | 41,522 | 4,396 | 8,141 | NL2SQL |
| CSpider | 多 | 中英 | 复杂 | 166/876 | 6,831 | 954 | 1,906 | CSpider |
| DuSQL | 多 | 中文 | 复杂 | 200/813 | 22,521 | 2,482 | 3,759 | DuSQL |
百度千言文本相似度,主要包含LCQMC/BQ Corpus/PAWS-X,见官网,丰富文本匹配的数据,可以作为目标匹配数据集的源域数据,进行多任务学习/迁移学习。
OPPO手机搜索排序query-title语义匹配数据集。
链接:https://pan.baidu.com/s/1Hg2Hubsn3GEuu4gubbHCzw 提取码:7p3n
-
用户查询及相关URL列表
| 数据集 | 数据概览 | 下载地址 |
|---|---|---|
| ez_douban | 5 万多部电影(3 万多有电影名称,2 万多没有电影名称),2.8 万 用户,280 万条评分数据 | 点击查看 |
| dmsc_v2 | 28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据 | 点击查看 |
| yf_dianping | 24 万家餐馆,54 万用户,440 万条评论/评分数据 | 点击查看 |
| yf_amazon | 52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据 | 点击查看 |
维基百科会定时将语料库打包发布:
只能自己爬,爬取得链接:https://pan.baidu.com/share/init?surl=i3wvfil提取码 neqs 。
CoNLL 2012 :http://conll.cemantix.org/2012/data.html
- 开源代码:https://github.com/google-research/bert
- 模型下载:BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
BERT变种模型:
| 模型 | 参数 | git |
|---|---|---|
| Chinese-BERT-base | 108M | BERT |
| Chinese-BERT-wwm-ext | 108M | Chinese-BERT-wwm |
| RBT3 | 38M | Chinese-BERT-wwm |
| ERNIE 1.0 Base 中文 | 108M | ERNIE、ernie模型转成tensorflow模型:tensorflow_ernie |
| RoBERTa-large | 334M | RoBERT |
| XLNet-mid | 209M | XLNet-mid |
| ALBERT-large | 59M | Chinese-ALBERT |
| ALBERT-xlarge | Chinese-ALBERT | |
| ALBERT-tiny | 4M | Chinese-ALBERT |
| chinese-roberta-wwm-ext | 108M | Chinese-BERT-wwm |
| chinese-roberta-wwm-ext-large | 330M | Chinese-BERT-wwm |
腾讯AI实验室公开的中文词向量数据集包含800多万中文词汇,其中每个词对应一个200维的向量。
https://github.com/Embedding/Chinese-Word-Vectors
https://github.com/ymcui/Chinese-RC-Dataset
最全中华古诗词数据集,唐宋两朝近一万四千古诗人, 接近5.5万首唐诗加26万宋诗. 两宋时期1564位词人,21050首词。
https://github.com/chinese-poetry/chinese-poetry
https://github.com/Samurais/insuranceqa-corpus-zh
英文可以做char embedding,中文不妨可以试试拆字
https://github.com/kfcd/chaizi
-
搜狗实验室提供了一些高质量的中文文本数据集,时间比较早,多为2012年以前的数据。
-
- 包含了中文命名实体识别、中文关系识别、中文阅读理解等一些小量数据。
- https://github.com/crownpku/Small-Chinese-Corpus
THULAC: https://github.com/thunlp/THULAC :包括中文分词、词性标注功能。
HanLP:https://github.com/hankcs/HanLP
哈工大LTP https://github.com/HIT-SCIR/ltp
NLPIR https://github.com/NLPIR-team/NLPIR