

Peer-to-Peer Search Engine for IPFS
Admarus unlocks the full potential of IPFS by making it searchable. It is an open, decentralized network of peers indexing their IPFS documents. Admarus relies on no central authority, and is censorship-resistant by design.
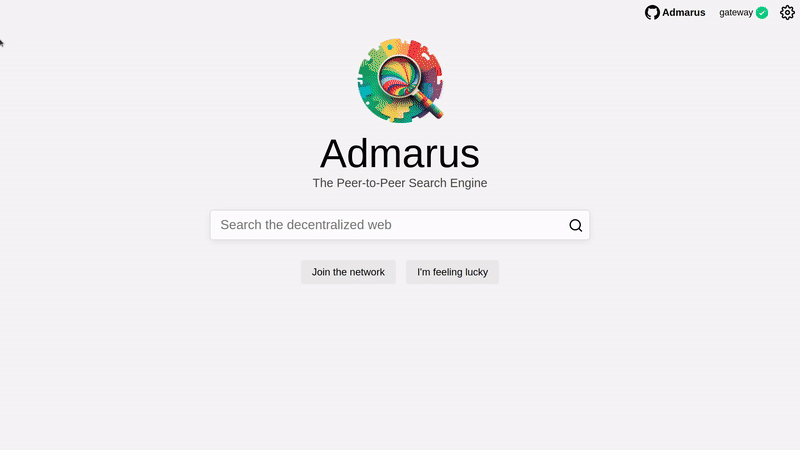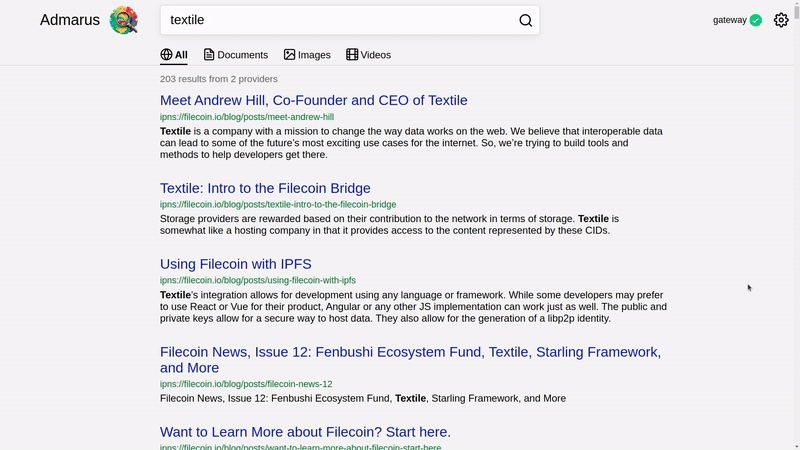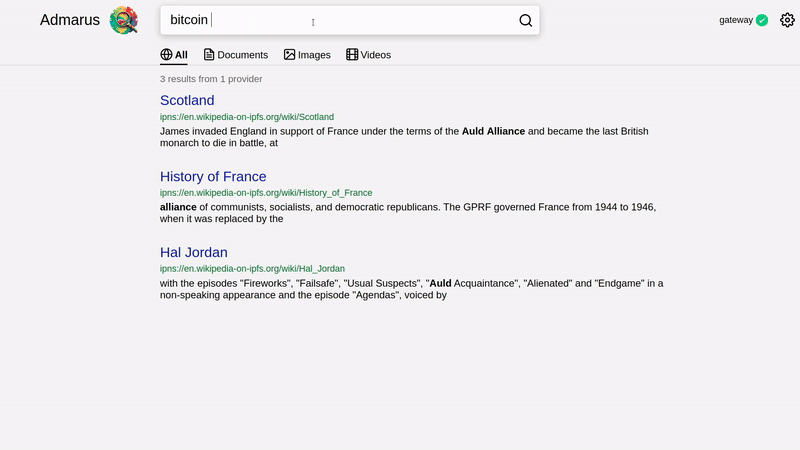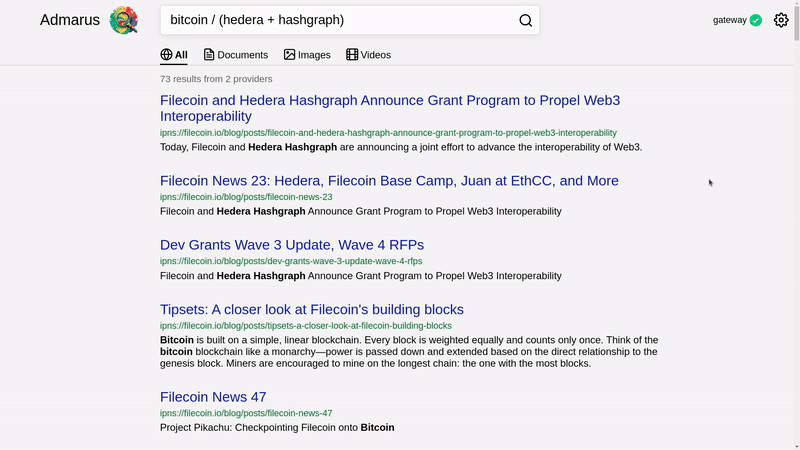
🔥 Try the gateway-based demo! 🔥
- No storage use: Admarus indexes data that's already in your Kubo node
- Search operators:
AND,OR, andNOT - Trustless: Results are verified, not trusted
- Language detection: Language is detected from text
- Scalable: Gets faster as more peers join
- Censorship-resistant: Censors would need full control of more than 95% of the network
- Open: Nodes don't discriminate on obscure criteria (hi emails)
- Decentralized: No central authority. Multiple peer discovery mechanisms available
- Blockchain-free: No blockchain, no token, just peer-to-peer magic
- Developer-friendly: Practical API for building apps and bots
There is no use in having a search engine if it breaks under load.
While previous attempts at building a peer-to-peer, powerful search engine have all failed, Admarus was designed with scalability in mind.
Actually, Admarus gets faster and more reliable as the network grows to thousands of peers.
This is all thanks to the Kamilata protocol and its routing algorithm for queries.
It allows Admarus to download results at constant speed, regardless of the size of the network.
Of course, the client cannot afford to download and rank millions of results, but we actually don't need a recall of 100%.
That's because some documents are more popular than others, and these are the ones we want to find.
(By default, 50% of the score of a document is based on its popularity.)
The more popular a document is, the faster we will find it, hence we don't need 100% recall to find the top n results.
I have only been able to run simulations with up to 30000 peers, so the behavior of the network with millions of peers is still unknown.
However, we can confidently say that Admarus can scale to at least a 200k peers and billions of documents.
Even if problems were to arise, these would be limited to queries made of a single common word, as for each additional term, you divide the pool of peers to query by a huge factor.
The current slowness of the network is due to the fact that there are not enough peers on it. They are doing their best at generating results for queries. Each result is generated from the document. The thing is, each document must be read from the Kubo store on the disk, which only yields 11 documents per second on my machines. As we parallelize the process by querying multiple peers concurrently, search will get significantly faster.
We have a publicly-editable wiki for guides and documentation.
Admarus is developped by Mubelotix, a french cypherpunk. Feel free to get in touch if you have any question or suggestion. I'm available to help people run nodes to make the network grow.
Admarus means Google in Gaulish (literally "very big").
Admarus is licensed under the GNU AGPL v3. However, the underlying Kamilata protocol uses the less restrictive MIT license.