1) 이미지에서 텍스트 추출하기 Gemini API를 사용하여 이미지 내의 손글씨 텍스트를 디지털 텍스트로 변환하는 방법을 살펴보겠습니다. Gemini Pro Vision 모델은 이미지를 분석하고, 그 안에 포함된 텍스트를 식별하여 읽어낼 수 있습니다. 예를 들어 회의 중에 작성된 메모나 중요한 손글씨 문서의 내용을 효율적으로 텍스트화할 수 있습니다.
prompts = ["asset/images/test_1.png", "Read the text in this image."]
chat_gemini(prompts)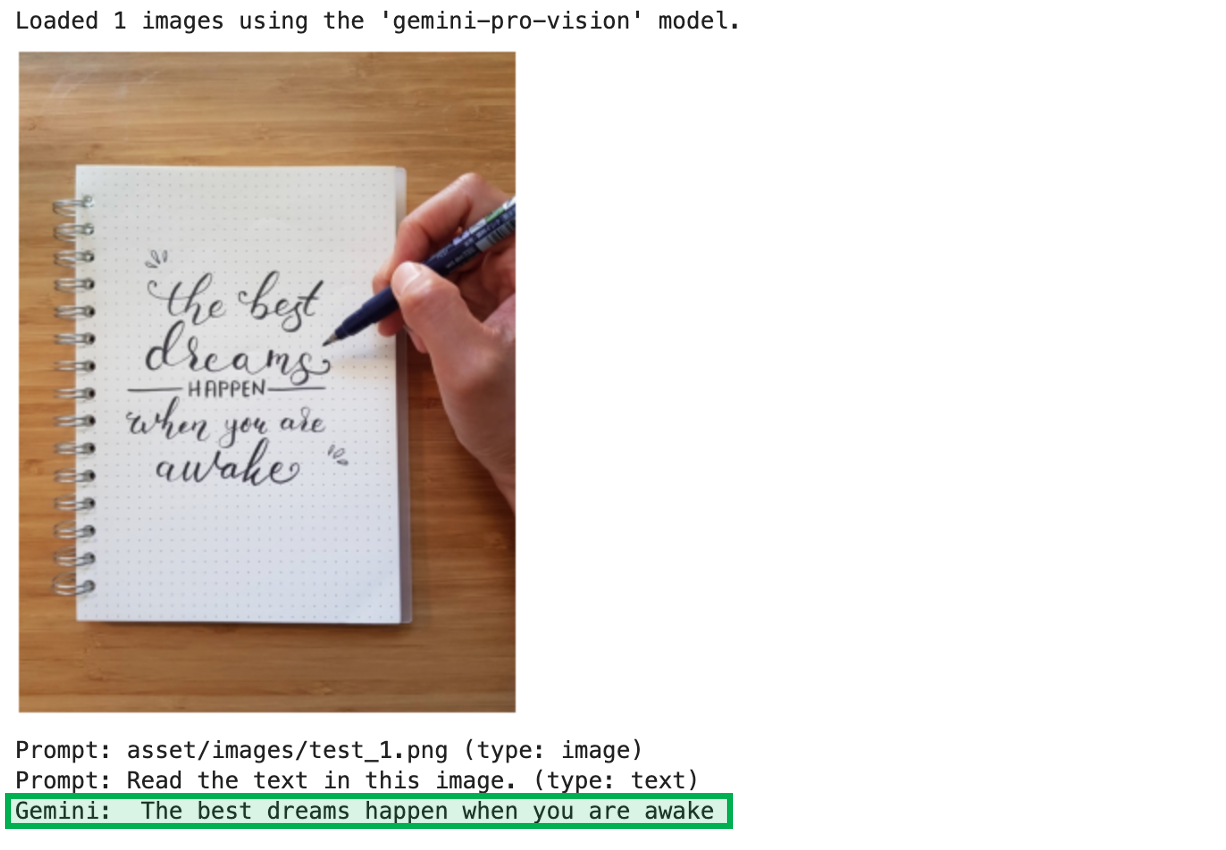
2) 몇 가지 예시로 이미지를 JSON으로 변환하기 Gemini API를 활용하여 제한된 수의 예시를 바탕으로 이미지의 내용을 JSON 형식으로 해석하고 질문에 답하는 방법을 찾습니다. 이 과정에서는 제공된 예시들을 참조하여 이미지 속 정보를 분석하고 질문에 답합니다. Gemini Pro Vision 모델은 멀티모달 데이터를 처리할 수 있는 능력을 갖추고 있어, 이미지를 분석하고 그 안의 정보를 구조화된 데이터 형식인 JSON으로 변환하는 것이 가능합니다. 예를 들어, 이미지에 포함된 객체, 사람, 장소 또는 활동에 대한 정보를 추출하고 이를 질문의 맥락에 맞추어 답변할 수 있습니다.
prompts = ["asset/images/test_2.png", "city: Rome, Landmark: the Colosseum",
"asset/images/test_3.png", "city: Beijing, Landmark: Forbidden City",
"asset/images/test_4.png",
]
chat_gemini(prompts)

3) 이미지 질문 답변 Gemini API의 이미지를 이용한 질문과 답변이 가능합니다. 예를 들어, 브라질너트의 이미지를 모델에 보여주고, 다른 이미지에서 해당 너트의 가격을 찾아낼 수 있습니다.
prompts = ["asset/images/test_5.png", "asset/images/test_6.png",
"What is the price of this?",
]
chat_gemini(prompts)
4) 이미지 텍스트를 JSON으로 변환하기 Gemini API를 사용하여 특정 이미지에서 텍스트 정보를 추출하고, 이를 JSON 형식으로 변환할 수 있습니다. 구체적으로는, 어시장 사진에서 물건들과 그 가격을 추출하고, 이를 구조화된 JSON 데이터로 출력하는 예시입니다. Gemini Pro Vision 모델은 이미지 속 텍스트를 인식하고 해석이 가능합니다. 어시장의 사진 속에서 다양한 물고기와 해산물의 이름과 가격 표시를 감지하고, 이 정보를 추출하여 JSON 형식으로 정리합니다.
prompts = ["Extract the items and prices from a fish market photo and output them in JSON.",
"asset/images/test_7.png",
]
chat_gemini(prompts)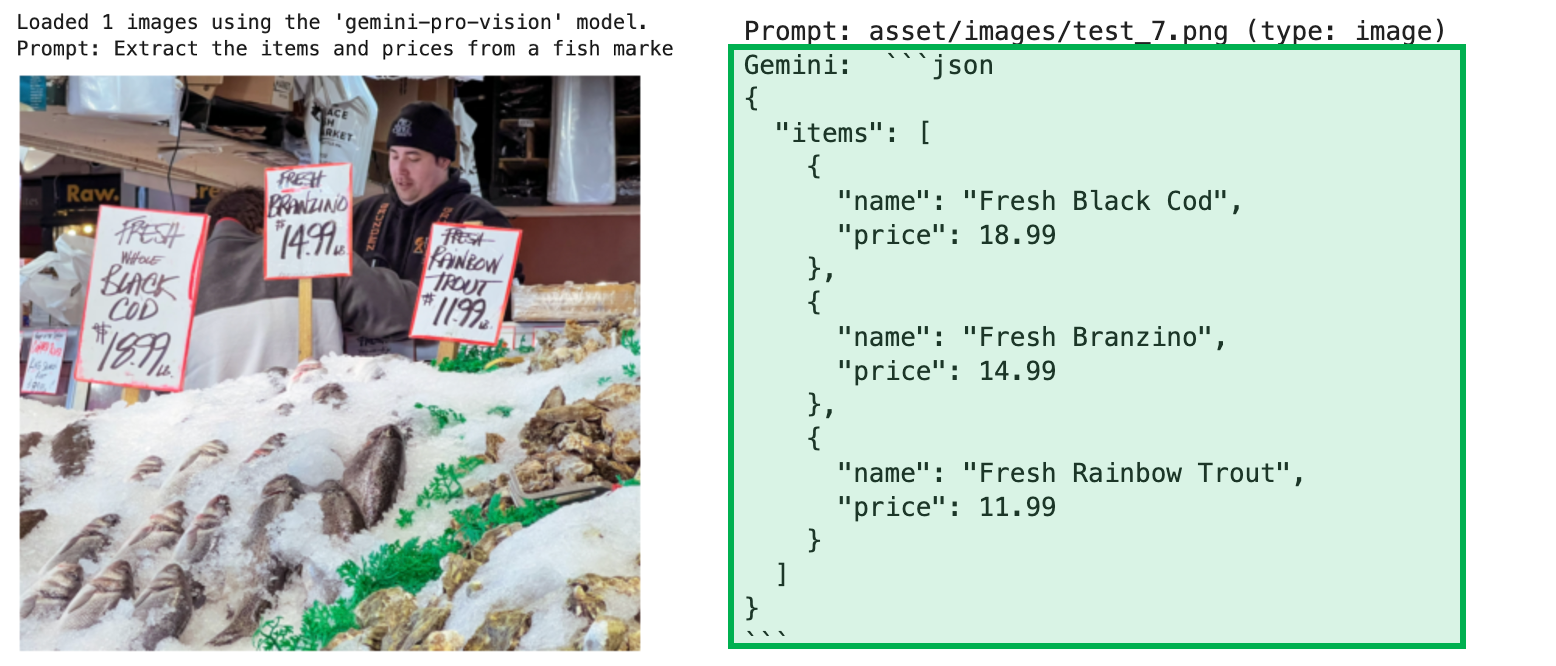
5) 이미지에서 이야기 만들기 Gemini API를 활용하여 이미지를 기반으로 창의적인 이야기를 작성하도록 할 수 있습니다. 구체적으로, 눈 속에서 스키 고글을 착용한 개의 이미지를 바탕으로 창의적인 이야기를 만들어냅니다.
prompts = ["asset/images/test_8.png",
"Write a creative story inspired by this image",
]
chat_gemini(prompts)
6) 추가 테스트 이외에도, Vertex AI에서 제공하는 샘플 외에 다양한 실험을 추가로 진행해 보았습니다.
prompts = ["asset/images/test_9.png",
"Just find the Audi car and tell me the number.",
]
chat_gemini(prompts)
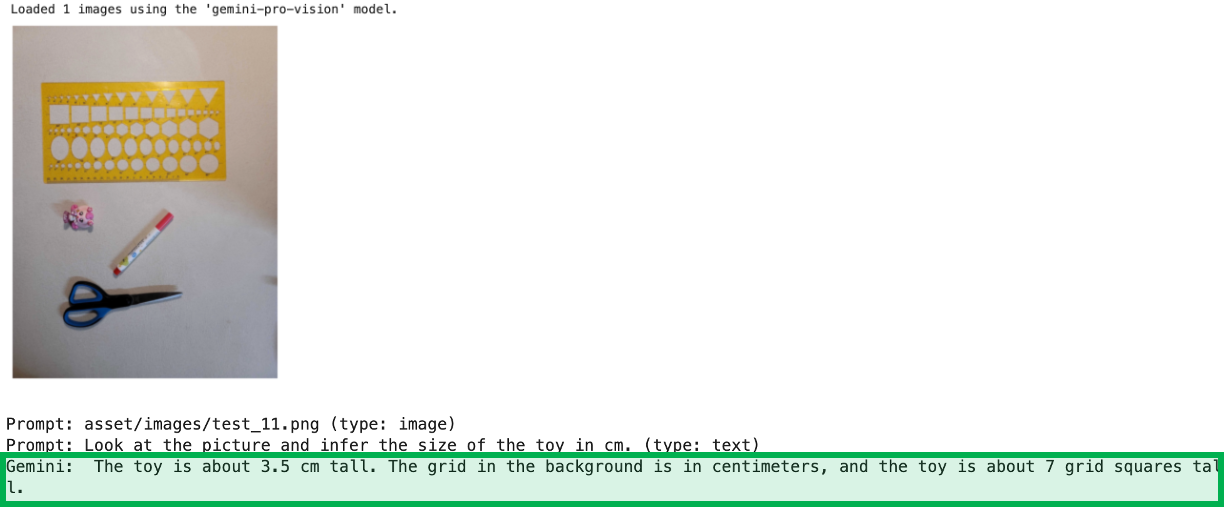
prompts = ["asset/images/test_10.png",
"Look at the picture and infer the size of the toy in cm.",
]
chat_gemini(prompts)