使用这份API,可以方便地调用 PaddleOCR-json 。比起Python原生的PaddleOCR库,PaddleOCR-json拥有更好的性能。你可以同时享受C++推理库的高效率和Python的简易开发。
请先在本项目 Releases 中下载OCR引擎二进制程序,然后将 python api (当前目录中的所有文件)下载到本地,即可通过python接口调用二进制程序。
Python API 拥有三大模块:
- 基础OCR接口
- 结果可视化模块,将OCR结果绘制到图像上并展示或保存。
- 文本后处理模块,支持段落合并、竖排文本整理等功能。
from PPOCR_api import GetOcrApi- 初始化OCR引擎进程
- 通过OCR引擎,执行一次或多次识图任务
- 关闭OCR引擎进程
接口: GetOcrApi()
参数:
| 名称 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| exePath | 必填 | str | 引擎二进制文件的路径,或远程服务器地址,见下。 |
| modelsPath | None | str | 识别库路径,若为None则默认识别库与引擎在同一目录下。 |
| argument | None | dict | 启动参数字典。可以用这个参数指定配置文件、指定识别语言。 |
| ipcMode | "pipe" | str | 进程间通信方式,可选值为套接字模式socket 或 管道模式pipe。 |
当前允许两种调用引擎的模式:
- 引擎部署在本地:
- 在 Releases 中下载OCR引擎二进制程序到本地,解压。
- Windows 平台:
exePath传入PaddleOCR-json.exe的路径。 - Linux 平台:
exePath传入run.sh的路径
- 引擎部署在远程:
- 在服务器上部署 PaddleOCR-json 程序,启用服务器模式,并确保客户机可以访问服务器。
- 客户机:
exePath传入"remote://ip:port"。
这个参数的本意是希望能自动处理相对路径在不同的工作路径下出错的问题。API在启动引擎进程时会将工作路径设置在引擎的父文件夹下,如果用户直接传入 models_path 路径到参数字典 argument 则很容易出现路径错误。而 modelsPath 参数则会先将输入的路径以当前的python运行路径为基准转换成绝对路径,之后再用 models_path 参数的形式输入给引擎,进而防止路径错误。当然,你也可以通过输入一个新的 models_path 参数到 argument 字典来覆盖掉这个路径。
返回值:
初始化成功,返回引擎API对象。初始化失败或连接远程服务失败,抛出异常。
示例1: 最简单的情况
ocr = GetOcrApi(r"…………\PaddleOCR_json.exe")示例2: 指定使用繁体中文识别库(需要先在引擎models目录内放入识别库文件)
注意,config_path的路径如果是相对路径,则根为PaddleOCR-json.exe所在的路径,而不是Python脚本的路径。
argument = {'config_path': "models/config_chinese_cht.txt"}
ocr = GetOcrApi(r"…………\PaddleOCR_json.exe", argument)示例3: 指定使用套接字通信方式
使用管道通信(默认)和套接字通信,在使用上而言是透明的,即调用方法完全一致。
性能上有微弱的区别,管道的效率略高一点,而套接字TCP在大型数据传输时(如30MB以上的Base64图片数据)可能稳定性略好一些。对于普通用户,使用默认设定即可。
ocr = GetOcrApi(r"…………\PaddleOCR_json.exe", ipcMode="socket")示例4: 使用套接字模式连接到远程服务器
在套接字通信模式下,你可以连接到一个远程的PaddleOCR-json服务器。这样一来就不需要将整套系统部署到同一台机器上了。
ip = '192.168.10.1'
port = 1234
ocr = GetOcrApi(r"remote://192.168.10.1:1234", ipcMode="socket")这里我们使用一个URI来代替引擎位置,表示服务器的IP和端口。接着用参数 ipcMode 来使用套接字模式(不可以用管道模式)。在这种情况下,输入 argument 参数不会有任何作用,因为这个python脚本并不会启动引擎进程。
在这种部署情况下,我们建议你使用方法 runBase64() 或者 runBytes() 来传输文件,方法 run() 的路径传输方式很容易出错。当然,你也可以禁用服务器的路径传输json命令image_path。
Python API 提供了丰富的接口,可以用各种姿势调用OCR。
方法: run()
说明: 对一张本地图片进行OCR
参数:
| 名称 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| imgPath | 必填 | str | 识别图片的路径,如D:/test/test.png |
返回值字典:
| 键 | 类型 | 描述 |
|---|---|---|
| code | int | 状态码。识别成功且有文字为100。其他情况详见主页README。 |
| data | list | 识别成功时,data为OCR结果列表。 |
| data | str | 识别失败时,data为错误信息字符串。 |
示例:
res = ocr.run("test.png")
print("识别结果:\n", res)方法: runBytes()
说明: 对一个图片字节流进行OCR。可以通过这个接口识别 PIL Image 或者屏幕截图或者网络下载的图片,全程走内存,而无需先保存到硬盘。
参数:
| 名称 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| imageBytes | 必填 | bytes | 字节流对象 |
返回值字典:同上
示例:
with open("test.png", 'rb') as f: # 获取图片字节流
imageBytes = f.read() # 实际使用中,可以联网下载或者截图获取字节流
res = ocr.runBytes(imageBytes)
print("字节流识别结果:\n", res)方法: runBase64()
说明: 对一个Base64编码字符串进行OCR。
参数:
| 名称 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| imageBase64 | 必填 | str | Base64编码的字符串 |
返回值字典:同上
方法: printResult()
说明: 用于调试,打印一个OCR结果。
参数:
| 名称 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| res | 必填 | dict | 一次OCR的返回结果 |
无返回值
示例:
res = ocr.run("test.png")
print("格式化输出:")
ocr.printResult(res)剪贴板相关接口已弃用,不建议使用
方法: runClipboard()
说明: 对当前剪贴板首位的图片进行OCR
无参数
返回值字典:同上
示例:
res = ocr.runClipboard()
print("剪贴板识别结果:\n", res)方法: isClipboardEnabled()
说明: 检测剪贴板功能是否启用。
无参数:
返回值
如果剪贴板已启用:True
如果剪贴板未启用:False
方法: getRunningMode()
说明: 检测PaddleOCR-json引擎的运行模式,本地或远程
无参数:
返回值字符串:
如果引擎运行在本地:"local"
如果引擎运行在远程:"remote"
使用示例详见 demo1.py
一般情况下,在程序结束或者释放ocr对象时会自动关闭引擎子进程,无需手动管理。
如果希望手动关闭引擎进程,可以使用 exit() 方法。
示例:
ocr.exit()如果需要更换识别语言,则重新创建ocr对象即可,旧的对象析构时也会自动关闭旧引擎进程。
示例:
argument = {'config_path': "语言1.txt"}
ocr = GetOcrApi(r"…………\PaddleOCR_json.exe", argument)
# TODO: 识别语言1
argument = {'config_path': "语言2.txt"}
ocr = GetOcrApi(r"…………\PaddleOCR_json.exe", argument)
# TODO: 识别语言2纯Python实现,不依赖PPOCR引擎的C++ opencv可视化模块,避免中文兼容性问题。
需要PIL图像处理库:pip install pillow
from PPOCR_visualize import visualize首先得成功执行一次OCR,获取文本块列表(即['data']部分)
testImg = "D:/test.png"
getObj = ocr.run(testImg)
if not getObj["code"] == 100:
print('识别失败!!')
exit()
textBlocks = getObj["data"] # 提取文本块数据只需一行代码,传入文本块和原图片的路径,打开图片浏览窗口
visualize(textBlocks, testImg).show()此时程序阻塞,直到关闭图片浏览窗口才继续往下走。
visualize(textBlocks, testImg).save('可视化结果.png')vis = visualize(textBlocks, testImg)
img = vis.get()以上show,save,get三个接口,均能开启或禁用指定图层:
isBoxT时启用包围盒图层。isTextT时启用文字图层。isOrderT时启用序号图层。isSourceT时启用原图。F禁用原图,即得到透明背景的纯可视化结果。
传入两个PIL Image对象,返回它们左右拼接而成的新Image
img_12 = visualize.createContrast(img1, img2)导入PIL库,以便操作图片对象
from PIL import Image接口创建各个图层,传入文本块、要生成的图层大小、自定义参数,然后将各个图层合并
颜色有关的参数,均可传入6位RGB十六进制码(如#112233)或8位RGBA码(最后两位控制透明度,如#11223344)
# 创建各图层
img = Image.open(testImg).convert('RGBA') # 原始图片背景图层
imgBox = visualize.createBox(textBlocks, img.size, # 包围盒图层
outline='#ccaa99aa', width=10)
imgText = visualize.createText(textBlocks, img.size, # 文本图层
fill='#44556699')
# 合并各图层
img = visualize.composite(img, imgBox)
img = visualize.composite(img, imgText)
img.show() # 显示使用示例详见 demo2.py
(text block processing unit)
import tbpu由 Umi-OCR 带来的技术。
OCR返回的结果中,一项包含文字、包围盒、置信度的元素,称为一个“文本块” - text block 。
文块不一定是完整的一句话或一个段落。反之,一般是零散的文字。一个OCR结果常由多个文块组成。文块后处理就是:将传入的多个文块进行处理,比如合并、排序、删除文块。
| 名称 | 方法 | 说明 |
|---|---|---|
| 优化单行 | MergeLine |
识别每一行文字,并整理所有行的顺序。 |
| 合并自然段 | MergePara |
合并属于同一自然段的文本。自动适应中/英文段落。 |
| 合并代码段 | MergeParaCode |
尽量还原图片中的空格缩进。适合识别代码图片。 |
| 竖排-从左到右-单行 | MergeLineVlr |
|
| 竖排-从右至左-单行 | MergeLineVrl |
向接口传入文本块列表(即['data']部分),返回新的文本块列表。
import tbpu
# 执行文本块后处理:合并自然段
textBlocksNew = tbpu.MergePara(textBlocks)执行后,原列表 textBlocks 的结构可能被破坏,不要再使用原列表(或先深拷贝备份)。
跟结果可视化配合使用:
textBlocks = getObj["data"] # 提取文本块数据
# OCR原始结果的可视化Image
img1 = visualize(textBlocks, testImg).get(isOrder=True)
# 执行文本块后处理:合并自然段
textBlocksNew = tbpu.MergePara(textBlocks)
# 后处理结果的可视化Image
img2 = visualize(textBlocksNew, testImg).get(isOrder=True)
# 左右拼接图片并展示
visualize.createContrast(img1, img2).show()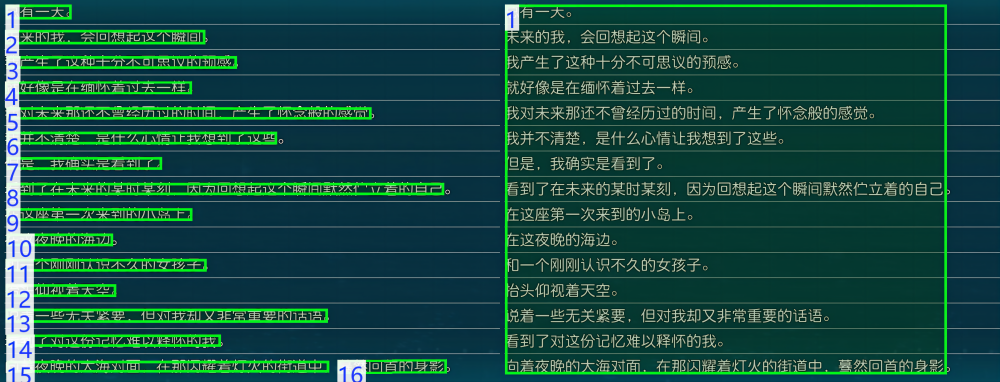
{kind=link}
使用示例详见 demo3.py